今天要和大家介 Google 在 2016 年發表的一種重量級的推薦算法 Wide&Deep 。它出自 Wide&Deep for recommendation 這篇論文,它當初運用在 Google App Store 的 APP 推薦,使得下載率大大的提升,也成為後來需多演算法是架在這個思維下再擴充。所以說這也是一個在推薦系統領域裡,非常具有里程碑意義的演算法。
在做推薦時,我們常會需解決 2 種情況:
第一種,明顯知道特徵與結果關係很強烈,無論他們中間過程是如何複雜,這種共現關係最好是被硬記、硬學起來,等下次再有類似場景時,不必再思考,就馬上拿出來用就好了!
第二種,對於沒見過,或是特徵與結果不明顯的事,那就要細細思考來龍去脈,把所有可能的因果關係全用上,再來做結論。
解決第一種情況,就稱它為 Wide ,就是要死背硬記所有對應規則,這就是傳統 LR 的絕活。
要解決第二種情況,就是深度學習的看家本領,它有辦法比對所有的特徵之間的關係,然後做出哪些特徵組合與結果是有關係的。這就稱他叫 Deep 。
現在問題來了,這Wide&Deep兩個東西要怎麼併在一起?
沒什麼特別的,看了還覺有點簡單粗暴。
Wide&Deep 還真的拿了兩個模型最後用 Sigmoid 結合起來。
一個模型是 DNN , 另一邊就是傳統的LR。
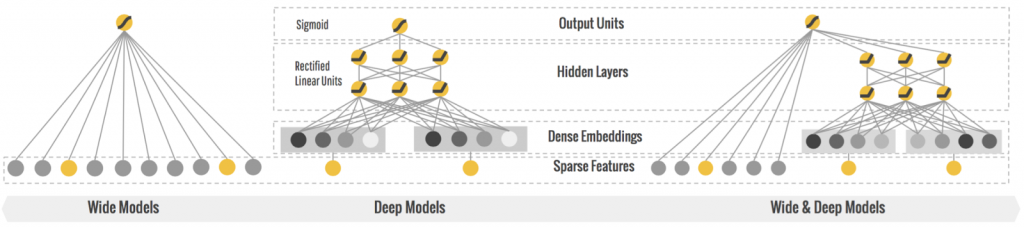
這邊是把輸入分為兩類:連續性特徵及分類特徵(離散特徵)。其中,分類特徵是做了 One-hot 編碼,然後再送到 embedding 裡去做轉換,然後與連續性特徵,共同做了三次的 Relu,最後再和另一邊的 LR (Wide 那部份)傳來的訊號,一起送進 Logloss 輸出層再輸出。
所以這部份負責的就是深度的部份 。
Wide 部份,用輸入,也是和 Deep 相同的特徵向量,只是它是用 交叉積變換層,來做到 LR 要做的事。
這部份的輸出,也是直接和 Deep 那邊一起送入 Logloss 裡,估最後的輸出。
到這邊,是不是覺得這個模型在解決問題上,是針對他們的需要去決。並且解決的思路並沒有特別的難懂,但對於他們的應用場景上,是非常有用的。
對了這個演算法,目前在 TensorFlow 上也有提供,大家也可以去玩玩。
Wide & Deep Learning: Better Together with TensorFlow

